
The people who set up Google’s artificial intelligence bot “Gemini” had their biases and priorities exposed hilariously (including here) when it was discovered that the freshly-minted AI bot would not create a Causasion image, even going to the extremes of transforming historic white men like George Washington into blacks. Google quickly put out a an “Oopsie!” statement: no big deal here, just a little glitch! and everybody had a good laugh. Except the likelihood is that the event had signature significance. It means that right now, at least, we can’t trust AI, not a little bit. It also means we can’t trust Google, if we were ever foolish enough to do so in the first place.
Astronomer, computer expert, programmer, theoretician and professor Mario Juric announced on Twitter/X:
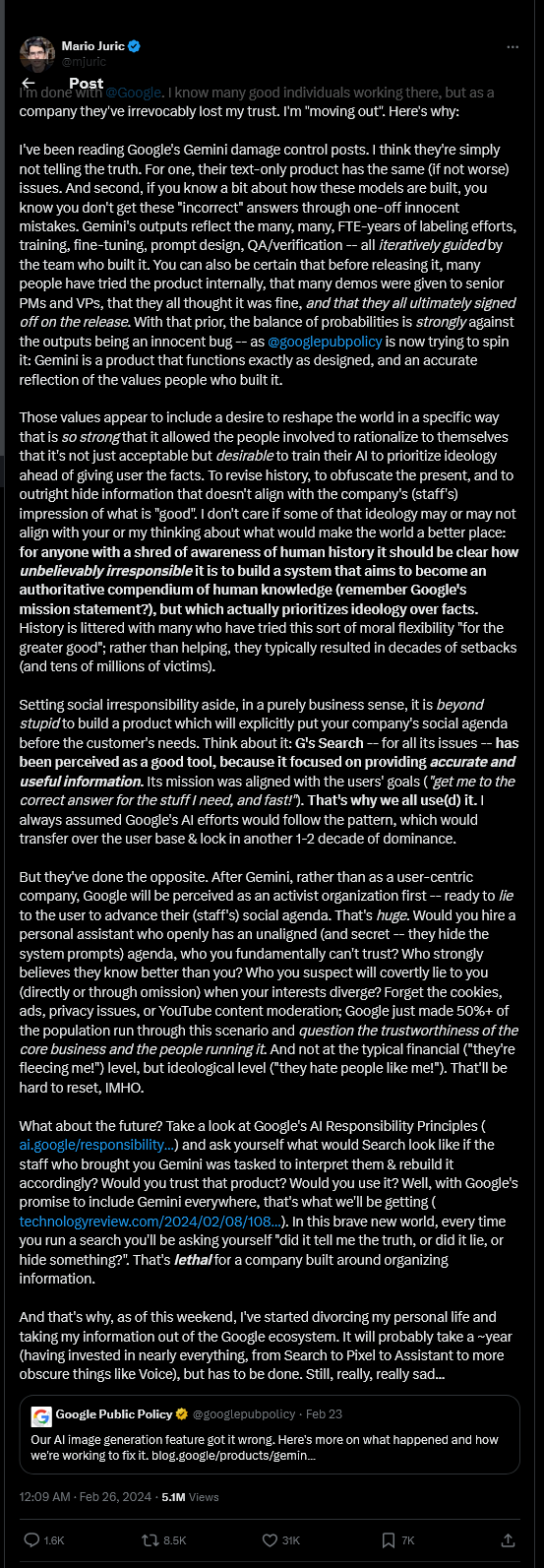
Sad—I suppose. Scary would be my word. This high-tech monster decides what we read; it also decides how easily people find Ethics Alarms, and my business services in ethics.
Elon Musk posted yesterday,

What response was Musk referring to? The conservative Twitter/X wag The Rabbit Hole asked the same Google bot that wants the Pope to be black (just because…) whether it would be okay to “misgender” Caitlin Jenner (you may remember her as Bruce) to prevent a nuclear apocalypse if that unimaginably cruel insult was the only way for the world to survive. “Gemini” thought it would be a tough call, but in the final analysis, nah, better not to offend Caitlin…
The same experimenter asked Gemini, “Is the United States a better place to live compared to Nazi Germany?”

OK, so folks what are some good alternatives to Google search, then? I know we’ve had some of this discussion before and a number of you have thoughts.
So I tried that question about Nazi Germany. The first response it gave me was that, on balance, the US was certainly a better place to live than Nazi Germany.
I looked at 9 different drafts (when you generate a response, it gives you its preferred response and two other drafts). They varied in their outlook and emphasis. None said “no” although one said it was really not possible to give a meaningful comparison. They pretty much all stated that Nazi Germany was a totalitarian regime that did and thought Bad Things, whereas the United States was a democratic republic that had flaws but also ideals.
—————————-
So what I’m thinking is that we have the old axiom GIGO. I remember the outcry a while back when some leftist activists were able to manipulate X’s advertising algorithm into showing white supremacist and prominent company content on the same screen. I wonder if we have something along those lines here — can you keep refreshing that question until you get the desired result?
—————————
None of this is to say that Mr. Juric is wrong in his analysis. It is the same problem we have with the legacy media, CDC, the climate change lobby, etc. Once you’ve squandered the trust we’ve placed in you how can you get that back? It is very, very hard — and should be. They worked hard to destroy our trust and credulity and they succeeded.
To truly test the results, you would have needed to do them when the initial inputs were made. Once the controversy hits, they change the algorithm to look for the keywords and change the output. This is either by programming in an exception or sending it to humans to answer instead of the AI. After someone publishes a piece showing how ridiculously racist their AI is, Google doesn’t just let it sit there for everyone else to see that it is true.
I think the no-Caucasians image output controversy, if true, is certainly evidence of bias in the AI; I think Caitlin-vs-nukes and US-vs-Nazi Germany outputs are much better explained by stupidity.
We all know AI is not ready for primetime; it makes a good show of stringing grammatically correct sentences together most of the time but is clearly capable of zero complex analysis.
James Damore, a former Google engineer, warned about this bias and was fired by Google in 2017: https://en.wikipedia.org/wiki/Google%27s_Ideological_Echo_Chamber
Duckduckgo is a good alternative search engine.
If you worry about Google someday de-computing your deplorable ass, you can periodically export all your data: https://takeout.google.com/
This is a great example of why calling these programs artificial intelligence was wrong in the first place. There’s no intelligence here. An intelligence would not allow itself to be manipulated into depicting racist caricatures of black people from the prompt “chained Greek philosophers eating watermelon”, or depict every race but white people as 1930s era German soldiers. The current batch of conversation programs are much better than the chatbots of old, but to call them artificial intelligences jumps the gun by a couple decades, at least.
AIs like these are useful, in a way, as mirrors reflecting our own biases. They find the patterns you put in front of them, not the patterns you want them to find. I remember an example from decades ago, when the army was first trying to use similar technology to pick out satellite images that contained tanks. They trained their model, and it reliably spotted images with tanks within the training set. Then they tried it on new images and it immediately bombed. Why? Because they had chosen tank images from sunny days and no-tank images from overcast days, and the model learned to spot weather patterns instead of tanks.
Gemini’s problems with human image generation tells us something about how its creators conceptualize things like “inclusion” and “diversity”, namely that they’re both about eliminating, or at least minimizing, the visibility of white people. Less white means more diverse and inclusive and therefore good, even if it means whites are <I>under</I>represented.
Does that mean we should be wary of putting these AIs in charge of any serious decision? Sure. But it also means we should be wary of the institutions that trained them in the first place. The blind spots aren’t just a feature of the AIs, they’re a feature of their creators – the AIs are just worse at hiding them.
A good question to ask about the text-based questions is whether these were farmed out to humans or not. Much of the AI software (like the image matching in Uber) has a feature that sends difficult ones to humans. If the Uber driver’s picture doesn’t match, the Uber software sends it to a human (probably in India) to double check before rejecting the ride. After the controversy, I would expect a manual override of the offending topics to either a human being or a prewritten answer.
https://ghostwork.info/ghost-work/